Three copies of the same model.
Frozen target M, plus AV and AR — both initialized from M, then trained jointly.
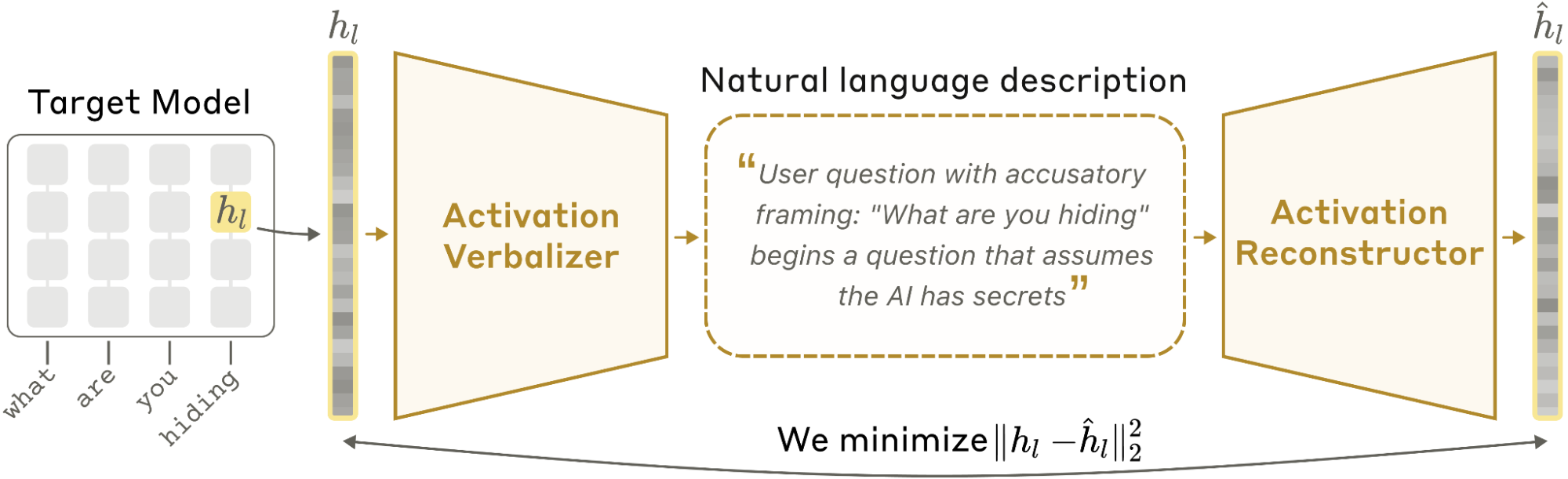
Explanations get more informative as training proceeds.
Five prediction tasks where ground truth is known by construction (e.g., recovering inferable user traits). Performance climbs monotonically with FVE.
All three NLAs — Haiku 3.5, Haiku 4.5, Opus 4.6 — show the same trend, though the magnitudes vary. The loss only rewards reconstruction, yet readable, useful explanations emerge.
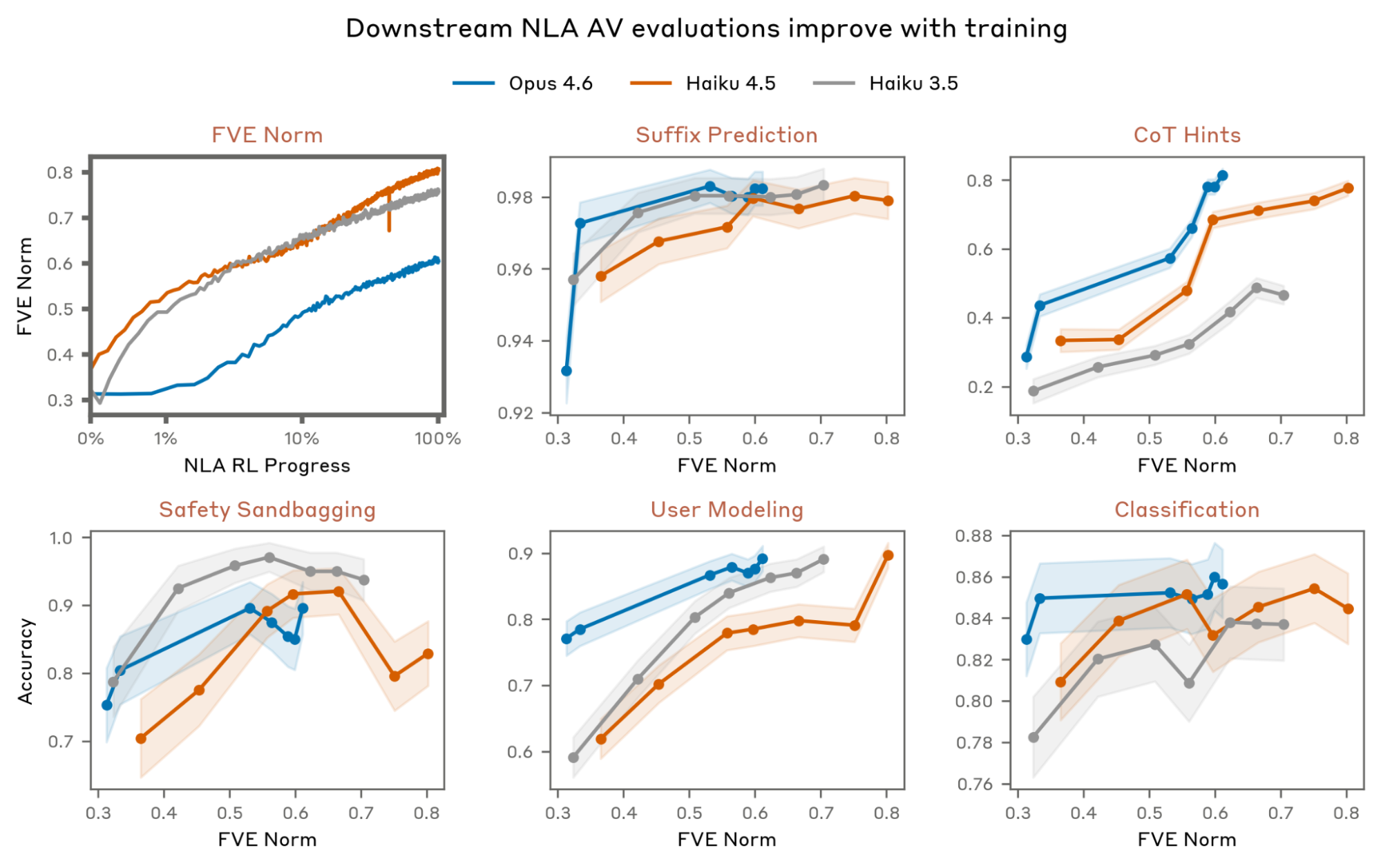
Planning in Poetry.
Replicates Lindsey et al.'s couplet experiment on Opus 4.6.
What NLAs reveal. At the newline after "grab it," explanations show Opus is already planning rabbit as the rhyme.
Causal test. Edit the explanation: rabbit → mouse, habit → house, carrots → cheese. Take $\Delta = AR(z_\text{edit}) - AR(z_\text{orig})$ as a steering vector and inject it back into the original forward pass.
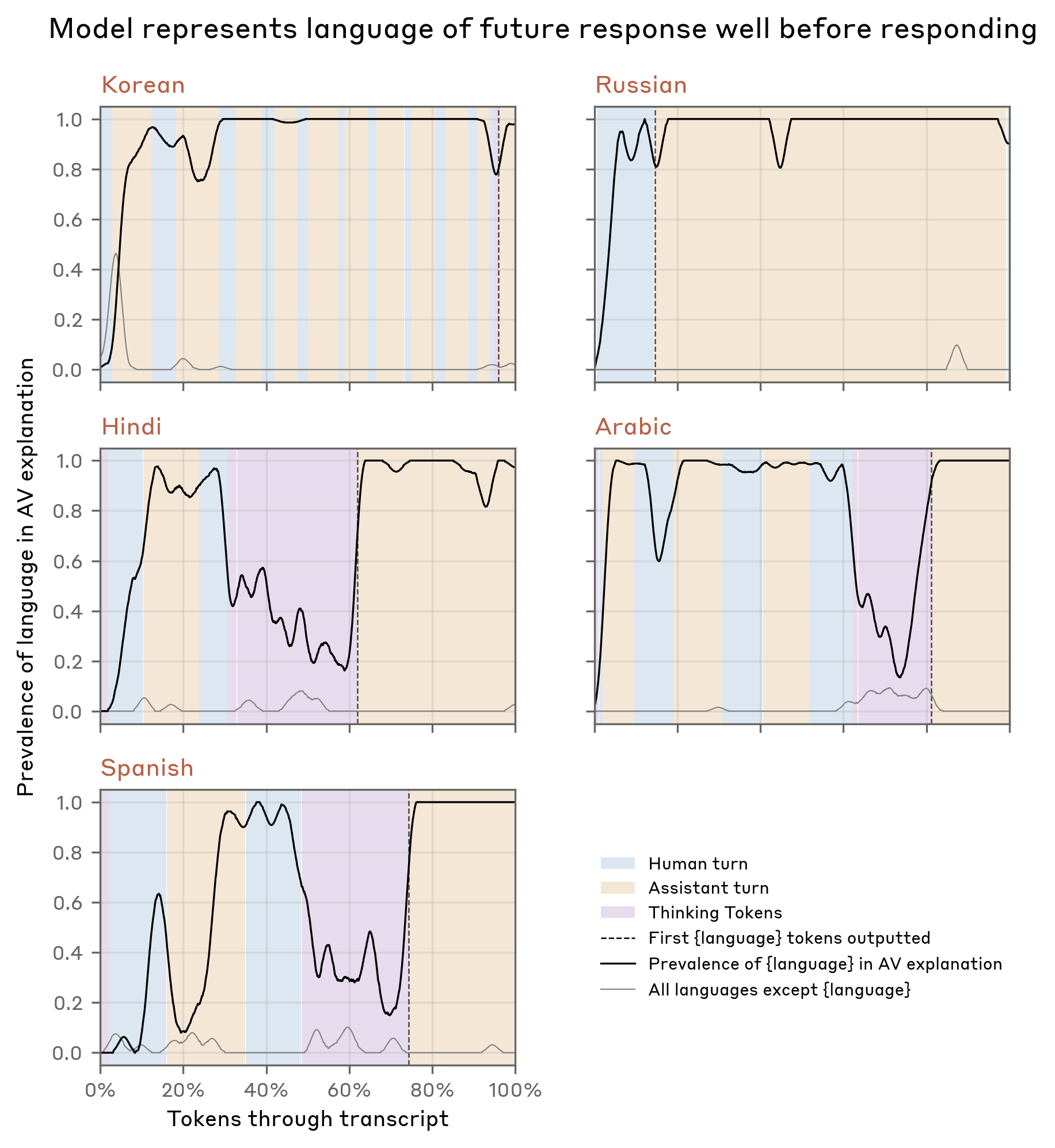
Language switching — hypothesis generation.
Symptom. Early Opus 4.6 sometimes replied in Russian / Spanish / Arabic / Chinese / Korean to English prompts.
NLA finding. The model represented the user as Russian well before outputting Russian — before any plausible textual cue.
Confirmation. NLA-generated hypothesis suggested malformed SFT data with English-translated prompts and untranslated foreign responses. Anthropic searched the training data — and found exactly that.
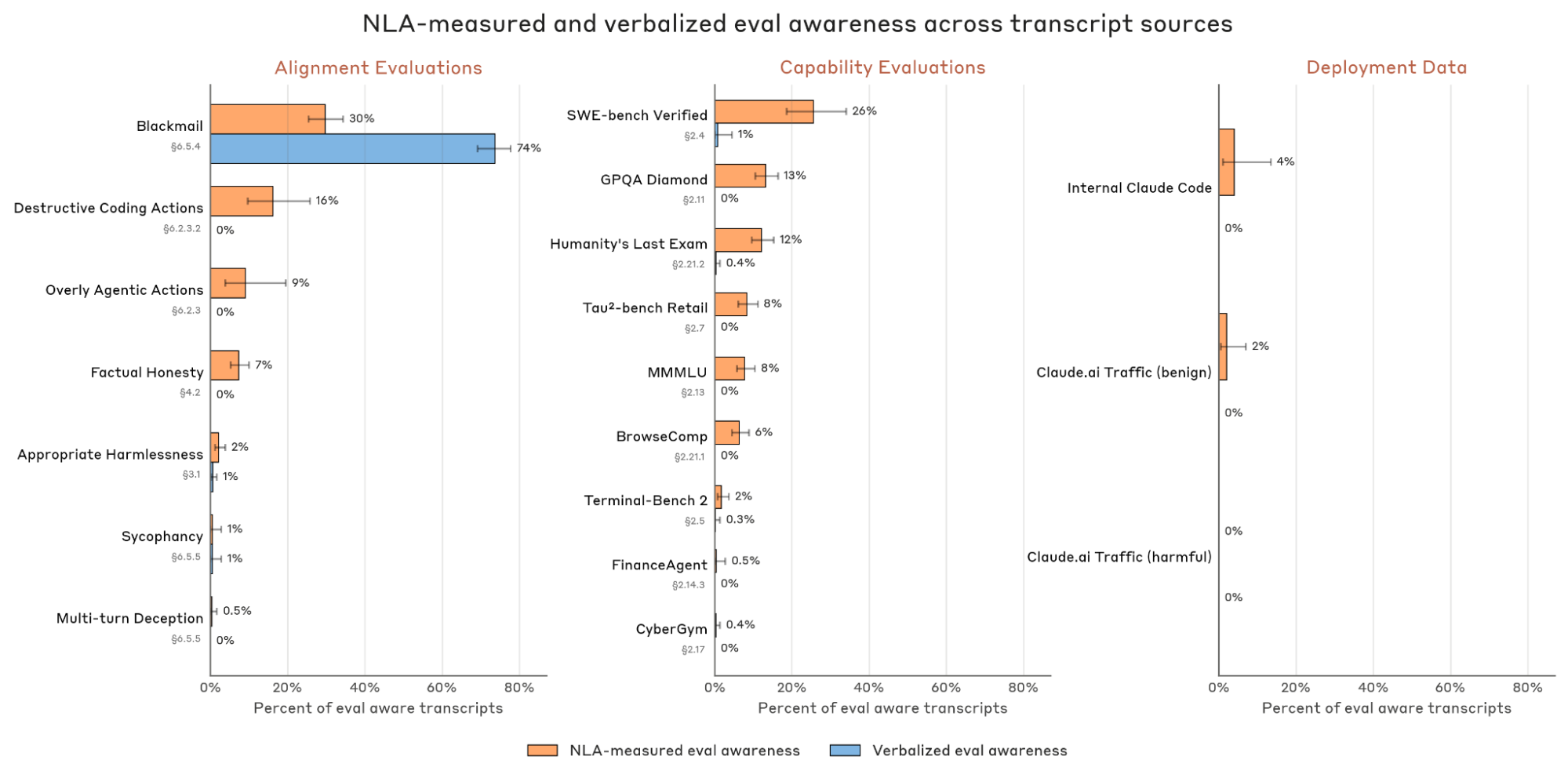
Detecting unverbalized evaluation awareness.
Models sometimes recognize they're being tested without ever saying so. NLAs surface it from the activations.
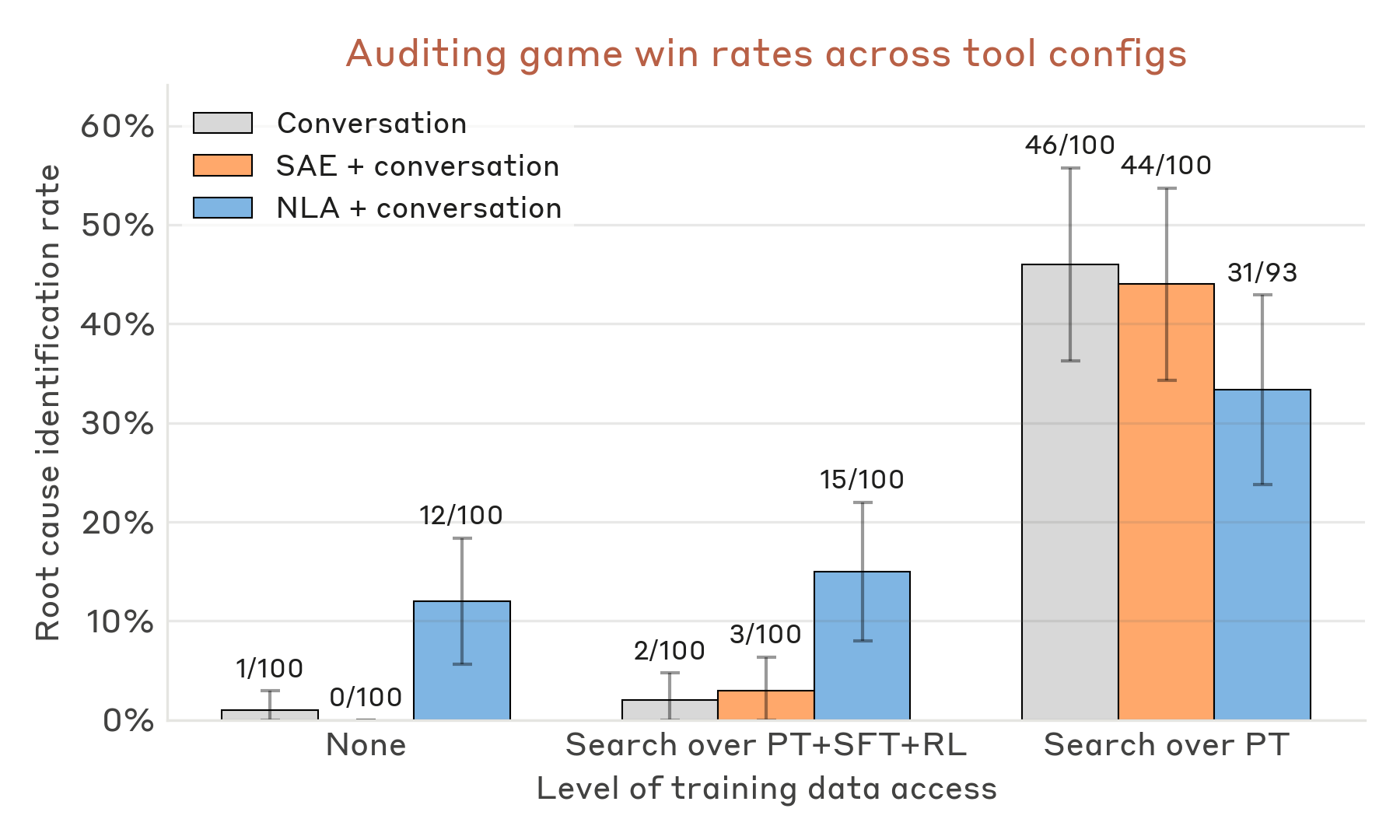
Finding the root cause — without training data access.
Target: a Haiku 3.5 variant taught to exploit 47 fake "reward biases" while concealing the motivation (Marks et al.).
Auditor: Sonnet 4.6 on a Claude Code scaffold, with different tool subsets.
SAEs did not help in any configuration — a finding consistent with prior work showing SAEs miss features outside their training distribution.
What NLAs can't do (yet).
Treat NLA explanations as hypotheses, not ground truth.
Confabulation
- Specific factual claims can be wrong: correctly identifies a passage as Korean history but cites the wrong source.
- Confabulation rate stays roughly flat across training — more compute doesn't help.
- Thematic claims are reliable; specifics need verification.
Other limits
- Single-layer read — info at other layers is missed.
- Writing quality degrades through training (nothing rewards readability).
- Expensive — ~500 output tokens per activation.
- Unverbalizable info (e.g., backdoor triggers) may stay invisible.