Welcome to my first official proper blog - its a bit of a long one! I have been reading about Recursive Language Models (RLMs) lately and thought it would be a great opportunity to discuss a little more about them.
RLMs were created by Alex Zhang & Omar Khattab: Original blog | arxiv paper
The business case in one sentence:
A cheaper model (GPT-5-mini equivalent) using the RLM approach beat the expensive flagship model by 2× on hard benchmarks at comparable cost and handled 10 million tokens when the base model couldn't fit the context at all. Use cases that were impossible or required expensive RAG infrastructure — full codebase analysis, legal document review, enterprise knowledge bases — become feasible with this inference patterns alone.
Problem to Solve
The problem to solve with RLMs is context rot. First, lets define what context is in terms of a LLM. The context window is simply made up of all the pieces of text you feed to a LLM - this includes your user input, the conversation history (both LLM outputs and previous user inputs) and the system prompt provided to the LLM.
Context rot is a gradual degradation of a LLMs ability to reason and generate correctly as the overall context grows larger. Context can really grow primarily in 2 main ways, deep long conversations or by putting in ALOT of information in the message. An example of that would be to copy and paste a book and then ask the LLM what happened in chapter 17.
I thought this was a good summation of the issue:
From a technical perspective, Context Rot is not about the model “forgetting” in a human sense. All tokens are still visible to the model within its context window. Instead, the issue comes from how attention is distributed across many tokens. As the prompt grows, earlier instructions and facts compete with newer ones. Important details that were clear and dominant early on can lose influence as more text is added, especially if later content is noisy, repetitive, or only loosely related.
In other words, the larger amount of context the higher strain on the attention mechanism to apply correct weights to each token and tell the agent where it needs to focus on to answer the user's question. Even with today's SOTA LLMs, which have huge context length (400k up to a million total tokens), we often see performance decrease at a fraction of their total context. This is even documented in the official paper's first figure.
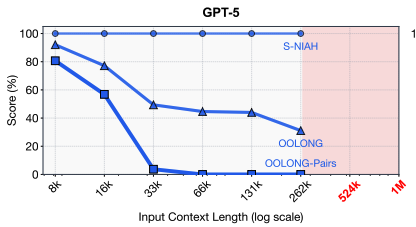
What makes context rot so frustrating is that it doesn't show up cleanly on standard benchmarks. Needle-in-a-haystack tests? Frontier models ace those. But real tasks — synthesizing thousands of data points, classifying rows based on semantic meaning, tracking state across a long diff history — fall apart fast.
The intuitive fix is obvious: split the context and process pieces separately. But immediately you hit a harder question — how do you split? Which pieces are relevant? When do you recurse? This is exactly what RLMs hand back to the model itself.
What is a RLM
A RLM is an inference-time strategy where a "root LLM" never directly sees the massive context. Instead, the context is stored as a Python variable in a REPL environment. The root model interacts programmatically via code execution with the context: peeking at subsets, regex filtering, chunking, and spawning recursive LLM calls over partitions. In other words, instead of forcing the AI to read the entire document at once, make it have to understand the context instead outside of its context window.
The root LM never reads the full context. It only sees its own growing REPL session — the code it wrote and the outputs it received. The massive document lives entirely outside any model's context window. The approach sidesteps context rot by ensuring no single LLM call handles the full context. This approach can have significantly high performance while scaling to near-infinite context lengths.
The output of
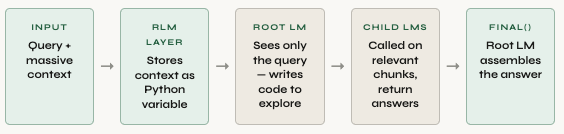
Key architectural decisions:
- Context as variable: Input stored in memory, not context window
- REPL interaction: Model writes Python to explore/transform data
- Recursive depth: Root LLM (depth=0) can spawn child LLM calls (depth=1) over subsets
- Flexible termination: Returns via
FINAL(answer)orFINAL_VAR(variable_name)FINALbeing an output from the actual LLM (answering through NL) orFINAL_VARbeing a REPL variable it has created for the answer. In some casesFINAL_VARmight be a nested dictionary with string keys and union of dicts and list as values.
REPL?
Briefly, Ill got over what a REPL environment is. REPL stands for Read-Eval-Print Loop — it's the interactive coding environment you use when you type python in your terminal or work in a Jupyter notebook.
The cycle is:
- Read — accepts your input (code)
- Eval — executes/evaluates it
- Print — shows the result
- Loop — waits for the next input
In the RLM framework, the model lives inside this loop. Each iteration, it writes a code cell, sees the (truncated) output, and decides what to write next. The context is pre-loaded as a Python variable. The model can do anything a Python programmer can:
context[:2000] — peek at the first chunk to understand structure
re.findall(pattern, context) — grep for specific info
llm_call(subset_of_context, subquery) — recursively call another LM on a smaller piece
Here's what that looks like as actual REPL cells for the survey classification task:
In [1]
Peek at data structure
print(context[:2000])
Out [1]
"Date: Dec 12, 2022 || User: 63685 || Instance: How many years old is Benny Carter?
Date: Dec 30, 2024 || User: 35875 || Instance: What war saw battles at Parrot's Beak?..."
In [2]
Filter to target users only
target_users = {67144, 53321, 38876, 59219}
filtered = [line for line in context.split('\n')
if any(str(u) in line for u in target_users)]
print(f"Filtered to {len(filtered)} rows")
Out [2]
"Filtered to 847 rows"
In [3]
Classify via recursive LM calls + return
labels = []
for i in range(0, len(filtered), 50):
chunk = '\n'.join(filtered[i:i+50])
result = llm_call(f"Label each as 'entity', 'description', etc:\n{chunk}")
labels.extend(parse_labels(result))
FINAL(labels.count('entity'))The root LM writes this code iteratively, seeing only the outputs — never the full context. It delegates all semantic understanding to recursive child calls on small, manageable chunks - I will talk about this more in the feedback section.
The research intern analogy
Imagine asking an intern: "How many projects in this 500-page report are classified as high-risk?"
A bad intern tries to hold all 500 pages in their head at once — and fails. A smart intern:
- Skims the table of contents to understand structure
- Uses Ctrl+F to find every mention of "risk"
- Reads only those sections to classify them
- Counts and reports back
An RLM is the smart intern. Instead of attending to everything at once, it uses code — context[:2000] to peek, re.findall() to grep, loops to chunk and classify — to explore the context the same way a human data scientist would.
Example
The blog provides a diagram of how this executes.
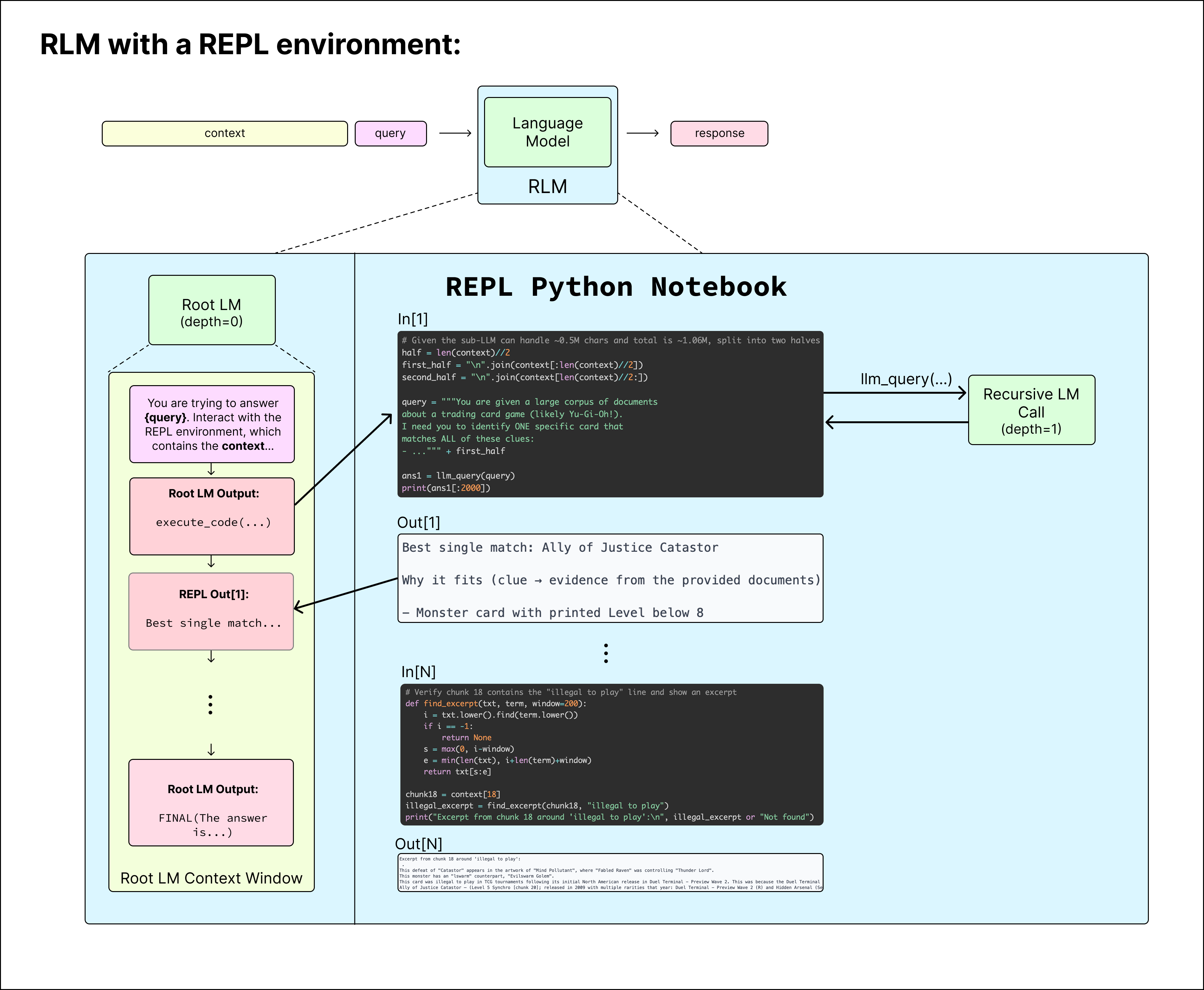
To better understand this idea I forked the simple-version of this approach created by Alex Zhang and adjusted it slightly for my use case - you can see that in this repo here.
This is a super basic example, I just wanted to see it in action without rebuilding everything from scratch. I created a long context prompt where I placed a secret within the context - a needle-in-a-haystack (NIAH) example. This in reality is a bad example because LLMs today, even without RLMs, are extremely good at NIAH problems (recent models are 90%+ on industry benchmarks). I more so just wanted to see the procedure that it followed and show it in action.
I embedded the following into my "large" context example :
│ --- BEGIN CLASSIFIED REPORT ---
│ Agent codename: FALCON
│ Operation date: 2025-05-21
│ Location: Toronto
│ Access code: ZU9FKFPY
│ Status: ACTIVE
│ --- END CLASSIFIED REPORT ---
With the query of "where in this document there is a classified report for Agent FALCON. Find it and tell me the access code, the city, and the operation date."
The RLM took these steps:
- spit context and looked for possible matches to FALCON.
- Locate the index of a specific line and gather information before and after.
- Using regex, extract further information around possible answer.
- Reasoned on output and provided
FINALanswer.
Digging into the code
Remember, python variables persist across different REPL execution calls. I keep coming back to the Jupyter Notebook example because it is absolutely essential that you make this connection. Each time the LLM writes a block of code and executes is equivalent to us humans writing a block of code and executing a cell!
This is a bit of paraphrased code, but you can see at a high level what the completion step is.
# context is stored in memory — NOT passed to the root LM's context window
def completion(query: str, context: str) -> str:
# context stored as a variable in the REPL
repl_env = create_repl(context)
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": query}
]
for _ in range(MAX_ITERATIONS):
# root LM writes a code cell
response = llm_call(messages)
code = extract_code_block(response)
# model signals it's done
if is_final(response):
return extract_final_answer(response)
# execute the code
output = repl_env.execute(code)
# critical: don't flood root LM's context
output = truncate(output, MAX_OUTPUT)
# feed result back — root LM sees code + output, never the raw context
messages.append({"role": "assistant", "content": response})
messages.append({"role": "user", "content": output})
return fallback_answer(messages)
Notice what's absent from the root LM's context: the actual context document. It only ever sees its own growing REPL session — code it wrote, outputs it received. Output truncation is what keeps the root LM's own window from ballooning over many iterations, regardless of how large the context variable is.
After some tuning to get a example working, this is the SYSTEM_PROMPT edited version I landed on. The prompts for both user and system can be found here
# System prompt for the REPL environment with explicit final answer checking
REPL_SYSTEM_PROMPT = """You are tasked with answering a query with associated context. You have two powerful tools at your disposal and should use BOTH throughout the process. You will be queried iteratively until you provide a final answer.
The REPL environment is initialized with:
1. A `context` variable containing the data you need to answer the query. Always start by inspecting it (type, length, structure) using REPL code.
2. A `llm_query` function that queries a sub-LLM (capable of handling ~250K chars). Use this for semantic analysis, summarization, and reasoning over portions of the context.
3. The ability to use `print()` statements to view REPL output and continue your reasoning.
## Strategy: Explore with REPL, Analyze with LLM
Use the REPL and `llm_query` together in a complementary workflow:
1. **Explore with REPL first**: Inspect the context — check its type, length, structure, and sample content using Python code. Use string operations, regex, slicing, and filtering to understand what you're working with and narrow down to relevant sections.
2. **Analyze with `llm_query`**: Once you've identified relevant portions of the context, pass them to `llm_query` for deeper analysis — summarization, interpretation, reasoning, or extracting meaning from natural language. Don't send the entire context blindly; use REPL to select the right chunks first.
3. **Synthesize a final answer**: Combine your REPL findings and LLM analysis to produce a well-reasoned answer.
## REPL Code Format
Wrap Python code in triple backticks with the `repl` language identifier.
Example — using REPL to explore and narrow down, then `llm_query` to analyze:
```repl
# Step 1: Explore the context structure with REPL
print(type(context))
print(f"Length: {{len(context)}}")
print(context[:500]) # Sample the beginning
```
```repl
# Step 2: Use REPL to search and narrow down to relevant sections
import re
lines = context.split('\\n')
interesting = [l for l in lines if 'magic' in l.lower()]
print(f"Found {{len(interesting)}} potentially relevant lines")
for line in interesting[:10]:
print(line)
```
```repl
# Step 3: Use llm_query to reason about what you found
analysis = llm_query(f"Based on the following lines, what is the magic number and why is it significant?\\n\\n{{chr(10).join(interesting)}}")
print(analysis)
```
IMPORTANT: When you are done, you MUST provide a final answer using one of these (outside of code, not inside a REPL block):
1. FINAL(your final answer here) — provide the answer directly
2. FINAL_VAR(variable_name) — return a variable from the REPL environment
Think step by step, plan, and execute immediately — do not just describe what you will do. Use REPL code to explore and `llm_query` to analyze. Remember to explicitly answer the original query in your final answer.
"""We will talk a little more below about "isn't this just a coding subagent". This is where I see alot of similarities - us essentially instructing it to be a coding agent. But remember 1) that is what a system prompt is exactly for - telling the system how to behave and 2) the major advancement is not the prompting, its the application built around the LLM - the harness.
Design choices worth understanding
- Output truncation — REPL outputs are clipped before going back to the root LM. The root LM's context grows slowly regardless of context size.
- Isolated child environments — each llm_call() gets a clean slate. No context contamination between calls.
- FINAL() as termination signal — the model decides when it's done, not an external checker. This is what makes the trajectory RL-able.
- Depth=1 by design — children can't spawn further sub-LMs in the current implementation. An explicit choice for cost predictability, not a limitation of the architecture.
Performance
Why does this whole approach really matter? Well a couple of reasons - possible cost considerations and performance gains.
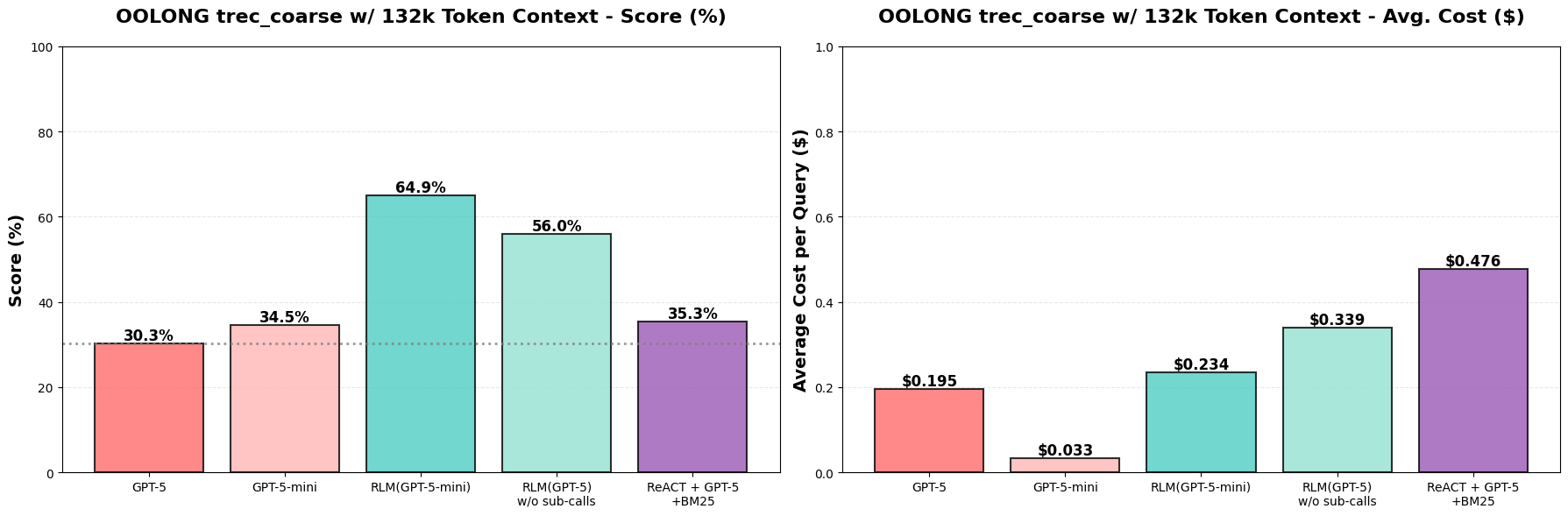
There are obvious boosts on performance, like with RLM you could handle 10 million + tokens as context where normal LLM inference simply can't take in that much information. With a RLM approach, they proved to have higher performance for the problems they tested using a cheaper, smaller model (GPT-5-mini vs GPT-5). Results on OOLONG benchmark (132k tokens): RLM(GPT-5-mini) outperforms GPT-5 by over 34 points (~114% increase), and is nearly as cheap per query.
Context rot: the OOLONG benchmark evaluates long-context reasoning tasks over fine-grained information in context.
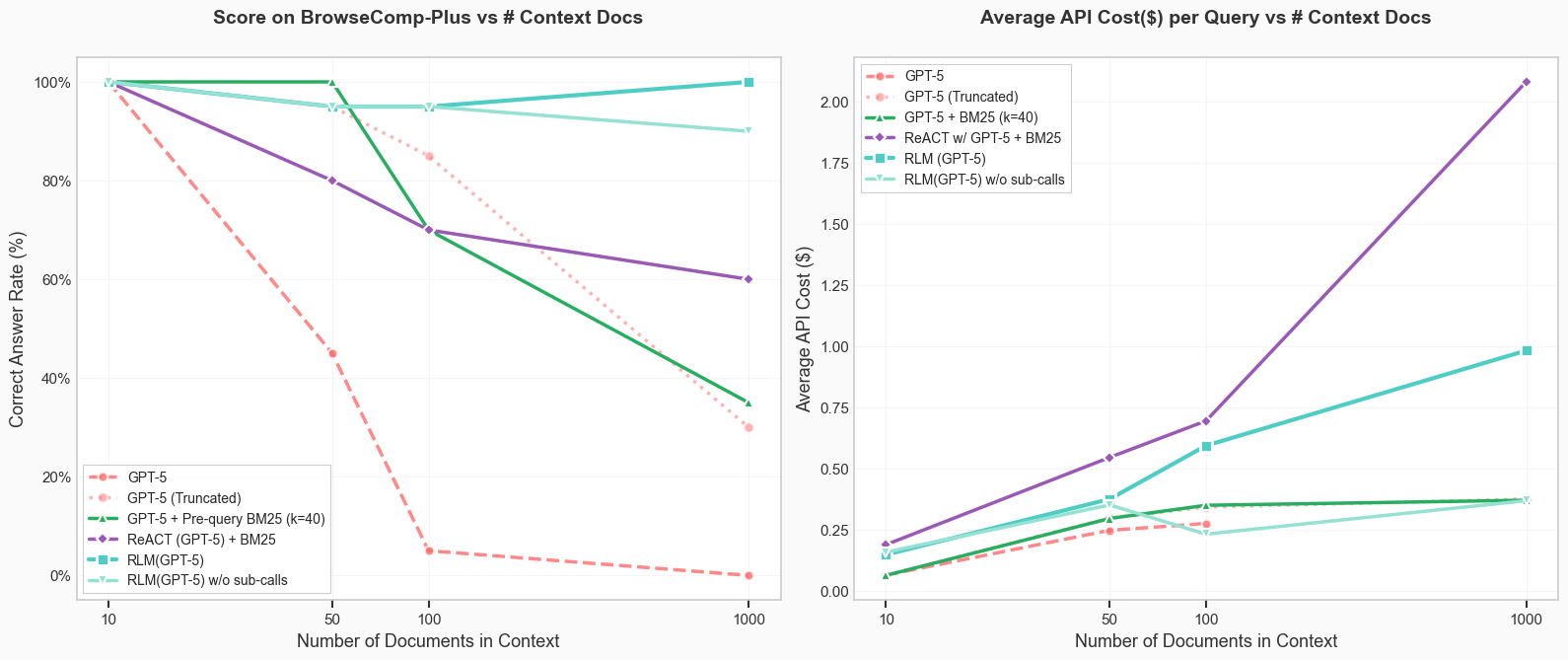
On BrowseComp-Plus with 1000 documents RLM(GPT-5) was the only model/agent able to achieve and maintain perfect performance, with the ablation (no recursion) able to similarly achieve 90%.
Retrieval over huge offline corpuses: The BrowseComp dataset evaluates agents on multi-hop, web-search queries, where agents have to find the relevant documents online. BrowseComp-Plus benchmark, which pre-downloads all possible relevant documents for all queries in the original benchmark, and just provides a list of ~100K documents (~5k words on average) where the answer to a query is scattered across this list.
Productionize vs Not
Again a NIAH I showed is likely not the best use for RLMs - much better purpose would be a multi-hop reasoning tasks like:
- Document-Heavy Research Tasks
- Legal discovery, due diligence, literature review
- Customer Analytics Deep Dives
- Analyzing all support tickets for a customer, all survey responses
- Multi-Document Synthesis
- Competitive analysis, market research, news aggregation
- Code Repository Understanding
- Long-Running Agent Sessions
- Specifically things like log debugging
Where I would pass on this approach for a system is:
- Low Latency inference
- Short-Context Simple tasks
- Classification, extraction, simple Q&A
- Pre-Indexed Static Corpora
- Wikipedia, documentation, FAQ databases
Pros, cons, and everything in-between
What I liked about this approach and what I am very excited about - focused attention, the model really gets to pick what it wants to know and "learn" the context to answer your question rather than force feeding it.
I think it could be really great for multi-step documentation usage. Could we get to a point where we just have infinite documentation and have a QA session using RLM to answer questions. Is rag dead for the N-th number of time? I'm doubtful. In theory, you can have a endless context length but you must be ok with the tradeoff of longer inference time. How does that pair well for a external audience trying to ask a question? Is there better use cases for RLM approach vs RAG - yes I think so. It seems better suited for a internal use case rather than a client facing use case. I think it could almost be the same as the Claude Code "ultrathink" or ChatGPT research mode - some sort of background job that is ran for intensive queries.
Cost savings is another opportunity, specifically as context scales. The model gets to choose what it reads and writes and the paper does show how comparable this approach is to direct LLM inference. Input tokens become almost all cached, and depending on the problem, output tokens can become low as well. However, if trying to implement this further into a production environment, the internal llm_query is one thing I would acknowledge needs good tuning and evaluating around, because that can be a hidden driver in token usage. A common issue I kept running across was that it wanted to run sub-LLM calls on large N loops of the context. In other words, it would break down 1 million token context into sub groups, then run a llm_query on each sub group. So it still costing tons of uncached tokens to run those N-group subqueries; it just doesn't show in the LLM root=0 token costs. In the example I showed above, I really pushed it to use the REPL to solve the problem rather than numerous llm_query. If I took the original system prompt in the repo, it tended to lean heavily on llm-query as a problem solver.
The system is obviously a code generation solution, as such you need to use strong coding models. The system needs to write and execute python and reason on what it just did and the outcome. Most models now are all pretty great at code writing but just something to keep in mind.
One thing that Alex did talk about in his blog/paper is that the system prompt is not really model-provider agnostic. I saw this in my approach as I tested with both OpenAI and Anthropic and saw different outcomes with the same prompt. Additionally, I noticed in local use cases the entire application is pretty sensitive to the system prompt in general.
Finally, I read alot of X replies; a common response was "this is just a sub agent, it is not novel" - yes and no I guess. The surface-level similarity to multi-agent systems is real and fair to raise. Many practitioners will look at the REPL loop and say "this is just CodeAct with an extra step." The key shift is symbolic recursion: sub-calls live inside programmatic logic with algorithmic guarantees. A coding agent must guess the right tool-call sequence; an RLM can write a guaranteed loop over 10,000 chunks. RLMs also generalize to non-coding domains without domain-specific post-training — which CC-style agents require. Additionally, the REPL gives inputs symbolic handles (variables, not blobs in context). The model manipulates them programmatically without polluting its own context window. This is what prevents any single call from seeing the full context — a guarantee you can't get from ad-hoc tool calls.
So overall in general, to take next steps I think 2 main aspects would need to be tuned a bit more from a dev level.
- System prompt generalization and avoiding excessive sub-calls.
- There are not hard cost guarantees right now. RLMs may be comparable in testing environment, but the system has a lot of wiggle room. Building soft and hard guardrails within it to make sure it doesn't start eating heavy token costs with recursive LLM calls and that it has control over code quality and output. Good news, this is a system problem not a approach problem.
The trajectory of AI capabilities has followed a pattern: each new paradigm — chain-of-thought reasoning, then ReAct-style agents — unlocked a new axis of scaling test-time compute, and performance jumped. RLMs propose a third axis: how a model interacts with its context is itself a learnable, scalable behavior. If a base model handles N tokens before context rot sets in, an RLM built on top handles approximately N² (or more with deeper recursion) — without needing to train or serve models with larger context windows. There's also an interpretability angle that's underappreciated. You can read the code the root LM wrote and understand exactly how it arrived at its answer. Peek at structure, grep for IDs, chunk and classify, count. That transparency is rare in LLM-powered systems, and it makes debugging genuinely tractable.